Spring Boot プロジェクト構成について
こちらの記事が大変参考になったので、 自分なりに噛み砕いた内容をアウトプットしていきたいと思います。
レイヤによる分類
Spring Bootに限らず、開発をしていると様々な機能・目的を持ったクラスを作成する必要が出てきますが、 その際にどのような基準で分類していくかという視点が大事になってきます。
基準となる考え方にはいくつかの種類がありますが、そのうちの一つとして、
の三つによる分類方法があります。
上記の3つのレイヤを基準にしたとき、 入力から出力までのデータの流れは、アプリケーション層→ドメイン層→インフラストラクチャ層の順番になります。
また、各レイヤ間の関係について、
という点についてしっかり理解しておく必要があります。 この理由については後述していきます。
アプリケーション層
Controller¶
リクエストを処理にマッピングし、結果をViewに渡すという画面遷移と、セッション管理。 処理はControlle上で記述せず、ドメイン層のServiceを呼び出す形にする。
View
クライアントへの出力を担う。Spring MVCでは、Viewクラスが該当する。
クライアントからViewへリクエスト
リクエストに対応したControllerの処理が行われる
Controllerはドメイン層からServiceの呼び出しを行う。
Serviceから返却された結果をControllerで受け取る
ControllerからViewにその内容を返す。
6.クライアントのブラウザにViewを出力する。
大まかではありますが、このような形で処理が行われます。
Form
これは参考記事からそのまま引用
画面のフォームを表現する。フォームの情報をControllerに渡したり、Contollerからフォームに出力する際に用いられる。 ドメイン層がアプリケーション層に依存しないように、FormからDomain Object(Entity等)への変換や、 Domain ObjectからFormへの変換は、アプリケーション層で行う必要ある。
Helper
Controllerの補助役。
Controllerでは処理のマッピングを行い、具体的な処理そのものはService層を呼び出すと記述したが、 FormからDomain Object(Entity等)への変換や、Domain ObjectからFormへの変換など、ドメイン層が他の層に依存してはいけないといった制約から 例外的にController本来の処理以外の処理を行う必要が生じるケースもある。その時に使われるのがHelper。
Helperが存在することで、Controllerの本来の処理を見通しをよくするといった利点もあるが、 Helperに関しては必ず必要なものとはいえないため、状況に応じて作成するしないの判断を行う。
ドメイン層
ドメイン層は、アプリケーションのコアとなる層である。 ビジネス上の解決すべき問題を表現し、 ビジネスオブジェクトや、ビジネスルールを含む(口座へ入金する場合に、残高が十分であるかどうかのチェックなど)。 ドメイン層は、他の層からは疎であり、再利用できる。
前述したとおり、Controlleはクライアントからのリクエストに対応した指示を送るだけで、処理すべき具体的な内容はドメイン層に委譲しています。 Controllerはクライアントからの要望を忠実にドメイン層に伝えますが、伝えるだけ伝えたら、その後の具体的な処理はドメイン層にお願いして、 ドメイン層がうまいことやってくれた結果をクライアントに返すという立ち回りなので、クライアントからの要望にアプリケーションが どのように応えるかというコアの部分はドメイン層で担う必要があるということです。
また、インフラストラクチャ層について、 詳細な部分については後述しますが、先にざっくりと特徴を言ってしまうと、「ドメイン層の実装を持つ層」と言えます。
ここで一旦、先ほど記述した
の部分に立ち戻ります。
ここまで説明した内容から
「ドメイン層はビジネス上の問題を解決する上でどのような処理が必要かを意識すべきで、 コントローラからどのように呼び出されるかを意識した設計はすべきでない」
「ドメイン層はインフラストラクチャ層に実装される立場にあるので、実装元であるドメイン層が、 実装先であるインフラストラクチャ層に依存するような設計をしてはならない」
ということが言えます。
ドメイン層が他の層に依存してはいけないのは、こういった理由があるからと言えるでしょう。
さて、前置きが長くなってしまいましたが、ドメイン層で扱われるものについて見ていきます。
Domain Object
Domain Objectはビジネスを行う上で必要な資源や、ビジネスを行っていく過程で発生するものを表現するモデル。 大きく分けて、以下3つに分類される。
EmployeeやCustomer, Productなどのリソース系モデル(一般的には、名詞で表現される), Order, Paymentなどイベント系モデル(一般的には動詞で表現される)、 YearlySales, MonthlySalesなどのサマリ系モデル
データベースのあるテーブルの、1レコードを表現するオブジェクトを表現するEntityは、Domain Objectである。
Repository
Domain Objectのコレクションのような位置づけであり、Domain Objectの問い合わせや、作成、更新、削除のようなCRUD処理を担う。 この層では、インタフェースのみ定義され、実体は、インフラストラクチャ層のRepositoryImplで実装されるため、 どのようなデータアクセスが行われているかについての情報は持たない。
Service
業務処理を提供する。 この処理も、トランザクション境界となる。
Serviceでは、FormやHttpRequestなど、Webに関わる情報を扱うべきではない。 これらの情報は、Serviceの前のApplication層で、ドメイン層のオブジェクトに変換されるべきである。
インフラストラクチャ層
インフラストラクチャ層では、ドメイン層(Repositoryインタフェース)の実装を提供する。 データストア(RDBMSや、NoSQLなどのデータを格納する場所)への永続化や、メッセージの送信などを担う。
RepositoryImpl
RepositoryImplは、Repositoryの実装であり、Domain Objectのライフサイクル管理を隠蔽する。 これにより、ドメイン層がどのようにデータアクセスされているか意識しなくて済む。 Spring Data JPAを使用する場合は、Spring Data JPAが実体を(一部)自動で作成する。
O/R Mapper
データベースとEntityの相互マッピングを担う。 JPAや、MyBatis, Spring JDBCが本機能を提供する。 特に、JPAを用いる場合はEntityManager、MyBatis2(TERASOLUNA DAO)を用いる場合は、QueryDAO, UpdateDAOが該当する。
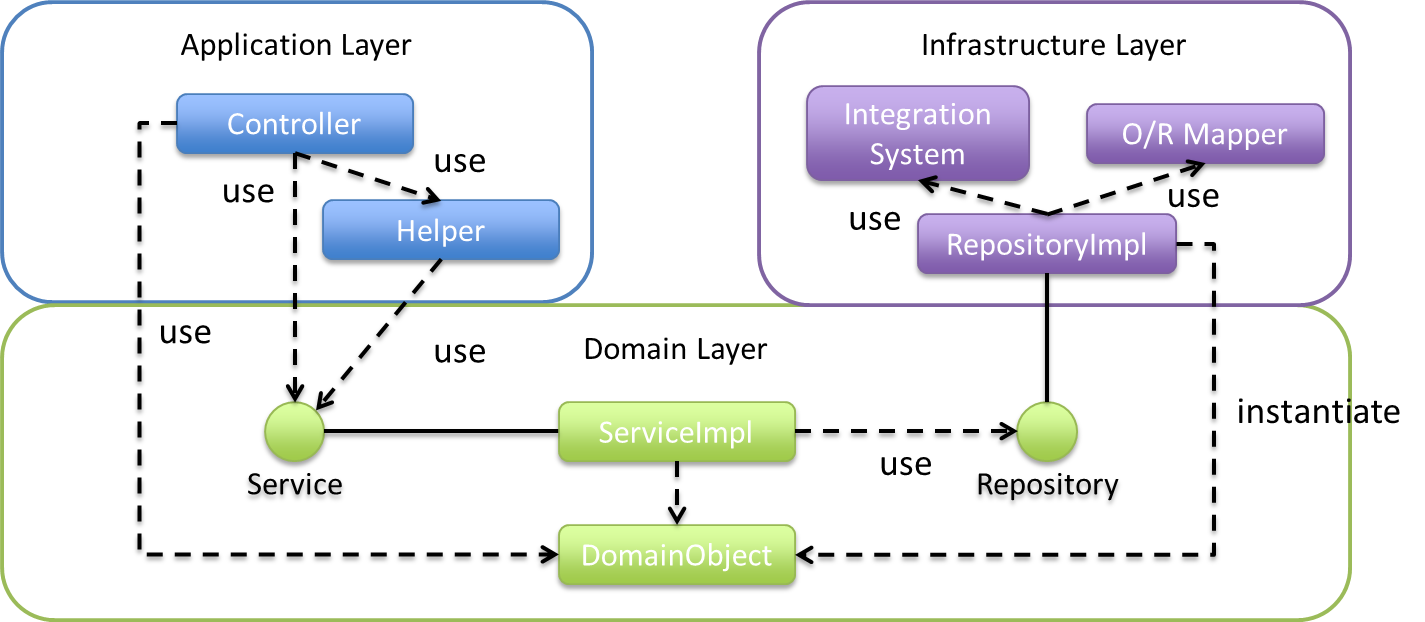
レイヤ間の依存関係
レイヤ間の結合部は下図のようにインターフェースとして公開する。 こうすることによって各層の実装に依存しない形式とすることができる。

※参考元より拝借。
{kind=link}
デザインパターン入門① Template Method
これまでデザインパターンの存在は知っていたが、きちんと勉強したことが無かったので、こちらの書籍とこちらの記事を参考に学習を進めている。
今回は第一弾として、Template Methodについて書いていこうと思う。
Templete Methodとは
一言で言ってしまえば、具体的な処理をサブクラスに任せるということを示したパターンのこと。
スーパークラスを定義し、その中では大まかな処理の枠組みを定義する。
そして、それらをサブクラスで継承し、具体的な処理はサブクラスで実装する、というものです。
クラス図で表すとこんな感じ。

斜体で書かれているメソッドはabstractメソッドであることを示しており、 ConcreteClass1,2で具体的な処理を実装しています。
また、上のクラス図ではAbstractClassに一つだけ具象メソッドがありますが、 この具象メソッドの中で具体的な処理の流れを定義しております。
具体例に置き換えて考える。
それぞれ下記の内容に置き換えて考えてみます。
AbstractClass : 動物
ConcreteClass1 : 人間
ConcreteClass2 : ネコ
人間、ネコはどちらも共通して「動物」であり、起きる()、食べる()、寝る()という共通の行動を取ります。 しかし、人間とネコでは食べ方や寝る姿勢、起きる姿勢などに違いがあります。
これをクラス図にして考えると、このような形になります。

つまり、このパターンで行っていることは、
「動物が取る行動は起きる、食べる、寝るで共通しているから、わざわざ「動物」に該当する各クラスで毎回実装させずに「動物」クラスで定義するけど(wakeUpAndEatAndSleep())、 人間とかネコでそれらの行動の特徴に違いはあるだろうから、そういうのは各々自分のクラスで実装してね。(wakeUp(),eat(),sleep())」
といったことをしていると考えることができる。
メリデメ
メリット
- ロジックの共通化、サブクラス設計の簡潔化
TemplateMethodパターンを用いずに、コピペで複数の「動物」の実装クラス「人間」、「ネコ」、「イヌ」、、、を作成した場合、 修正の範囲が全体に及んでしまいます。
動物として取りうる行動が共通しているのであれば、各サブクラスで実装するのではなくスーパークラス側で共通の処理として持たせることができ、 そうすることでサブクラスの設計が簡潔になり、修正が必要になった際もスーパークラスのロジック一箇所の修正で対応が可能になります。
デメリット
- 親と子の関係が密接なので、スーパークラスで定義している処理の内容を把握する必要性アリ
サブクラス側で共通ロジックの記述は必要なくなりますが、共通ロジックの内容を意識しなくていいという訳ではありません。 「人間」「ネコ」「イヌ」のサブクラスはどれも「動物」に集約されるため、開発者は動物として取りうる行動が何なのかを把握し、 その行動に対応した細かな違いをサブクラスごとに実装していく必要があります。
- スーパークラスの処理が大きくなると、サブクラスの自由度が減少する
スーパークラス側で処理の大枠を固めてしまうため、その内容が大きければ大きいほど、 サブクラス側での自由度は減少してしまいます。
ソースコード
public abstract class Animal { public abstract void wakeUp(); public abstract void eat(); public abstract void sleep(); public void wakeUpAndEatAndSleep() { wakeUp(); eat(); sleep(); } }
public class Human extends Animal { @Override public void wakeUp() { System.out.println("おはようございます。"); } @Override public void eat() { System.out.println("いただきます"); } @Override public void sleep() { System.out.println("おやすみなさい"); } }
public class Cat extends Animal { @Override public void wakeUp() { System.out.println("にゃー"); } @Override public void eat() { System.out.println("むしゃむしゃむしゃ"); } @Override public void sleep() { System.out.println("zzz..."); } }
public class Main { public static void main(String[] args) { Animal human = new Human(); Animal cat = new Cat(); System.out.println("---人間---"); human.wakeUpAndEatAndSleep(); System.out.println("---ネコ---"); cat.wakeUpAndEatAndSleep(); } }
▼実行結果
---人間--- おはようございます。 いただきます おやすみなさい ---ネコ--- にゃー むしゃむしゃむしゃ zzz...
ラムダ式とStream API
最近atCoderを始めて、簡単な配列操作については書けるようになってきたので、次のステップとしてStream APIを使用したコーディングができるよう覚えたことをメモしておきます。 ラムダ式も一応の理解はありますが、実際に書くということに慣れていないので、こちらの記事ではラムダとStream APIの両方について書いていきたいと思います。
ラムダ式とは何か
端的に言うと
[引数] -> [処理]
の形で記述することで無名クラスの記述を簡略化できるようにしたものです。 以降で順を追って説明していきます。
ラムダ式登場前の話 無名クラスという考え方
java7以前では、ラムダ式で行っていることを、無名クラスというものを使用して実現していました。
interface Calculator { int culc(int a , int b); }
このようなインターフェースがあった場合、実際に使用する際には、Calsuratorインターフェースを実装したクラスを作成する必要があります。
しかし、他で再利用する予定がなく、その場限りで必要であるメソッドであった場合、それだけのためにわざわざ実装クラスを作成するのは面倒です。 そういった場面で使われるのが、「無名クラス」です。
Calculator c = new Calculator() { pubic int culc (int a, int b ) { return a + b; } };
通常であれば、あらかじめ作成しておいたCalcuratorインターフェースの実装クラスを、変数cに代入する必要がありますが、 無名クラスでは変数に直接代入する形で実装クラスを作成しております。
その場限りで使用する一時的なものである場合、他で使われることがないため、実装クラスの名前が何であるかを意識する必要がなく、 calc()メソッドをオーバーライドした実装クラスの処理がどのような内容になっているかだけ分かれば良いということです。
上記のサンプルコードを、下記のように置き換えて読むと、分かりやすいかと思います。
new Culculation()⇒ CalculationImplクラス(仮名。実装クラスであるということを表現しているだけで名前は何でもいいです。){}内の記述 ⇒ CalculationImplクラスでオーバーライドしたcalc()メソッドの処理
本題のラムダへ
インターフェースの実装クラスの作成が、無名クラスという考え方により省略されただけでもかなり便利な気がしますが、 ラムダは更に簡単な記述で同様のことをやってのけます。
先ほどの無名クラス、元となるインターフェースが抽象メソッドを一つしか持たない場合、更に省略できる箇所があります。 それは、「メソッド名」と「引数の型」です。
無名クラス
Calculator c = new Calculator() { //① pubic int culc (int a, int b ) { //② return a + b; } };
① 変数cに代入されるべきはCalculatorの実装クラスであり、それ以外はない。ならばわざわざ書く必要もない ⇒ ラムダ式では省略
② メソッドが1つしかないのであれば、メソッド名や必要とされる引数を記述しなくても、どのメソッドを呼び出しているのだろう?となることがないため、わざわざ書く必要がない ⇒ ラムダ式では省略
Calculator c = (a,b) -> {return a + b};
恐ろしく簡単になりましたね…!
ちなみに、抽象メソッドを一つしか持たないインターフェースのことを「関数型インターフェース」と呼びます。 ラムダ式でも、無名クラスの時と同様に実装クラスの作成が行われていますが、省略に省略を重ね、 引数を渡して、処理を行うという記述に限定されたことで、関数のような使い方ができるため、 このような呼ばれ方をしています。
Stream API
次に、Stream APIについて説明していきます。
Stream APIはIterationを拡張したAPIで、コレクションに対して行う複雑な処理を簡略化して記述することができます。
▼Stream APIの処理の流れ
生成処理 データ列をStreamオブジェクトに変換
中間操作 データを操作する
末端操作 データを出力する
この処理の過程で、ラムダ式を使っていきます。
関数型インターフェースはわざわざ自分で作らなくても大丈夫
上述したように、ラムダ式は「関数型インターフェース」でないと使用できません。 「ラムダ式のために、関数型インターフェースをあらかじめ作らないといけないの…?」と思われるかもしれませんが、 その必要はありません。下記のような関数型インターフェースがあらかじめ用意されています。
抽象メソッド
R apply(T t)
T型変数tを引数に取り、R型に変換して返す
抽象メソッド
void accept(T t)
戻り値なし。T型の変数tを引数に取る
抽象メソッド
T get()
引数なし。T型で結果を返す
抽象メソッド
boolean test(T t)
T型の変数tを引数に取り、booleanで返す。
これらのインターフェースをラムダ式で扱うことで、 コレクションの操作を簡潔に扱うことができます。
Stream APIにはコレクションの操作を行う便利なメソッドがありますが、 それらのメソッドの中には上記のインターフェースを引数に取るものが数多く存在します。
つまり、メソッド呼び出し時の引数の中にラムダ式を記述するということになります。
長くなったので、続きは次回。
Spring boot事始め
Spring bootとは?
Spring Frameworkは2002年に登場したフレームワークで、当初はDI(Dipendency Injection:依存性の注入)と呼ばれる機能を実現するための小さなフレームワークでしたが、次第にDIをベースとする様々な機能が実装され、今では「統合フレームワーク」と呼ばれる大規模なものへと成長していきました。そんな、統合フレームワーク「Spring Framewrok」の中でも、「Webアプリケーション開発のためのフレームワーク」として多くのJavaプログラマに支持されているのが「Spring Boot」です。
Spring Frameworkよりも使いやすく、開発者にとって手軽なものとして現在多くの人に利用されています。
なぜ、Spring FrameworkではなくSpring bootを使うのか
上述したように、Spring BootはSpring Frameworkに内包される、コンポーネントの一つに過ぎません。 であれば、Spring Frameworkを使えばいいじゃん!と思うかと思いますが、Spring Frameworkは巨大なフレームワーク群となっているため、アプリケーション開発時に行う設定など、厳密な定義を必要とし、また、その設定も非常に煩雑なものとなってしまい、結果として開発者にとってハードルの高いものへとなってしまいました。
Spring FrameworkではXMLで設定の記述をしていましたが、これがなかなかの記述量で面倒。 しかもちょっとでも記述を誤ると想定した動きにならないという点が開発者にとってハードルの高いものとなり、敬遠されてきました。
この問題をSpring BootはAuto Configurationという機能を作ったことで解消しました。
Spring Initializerを使ったプロジェクトを例に特徴をつかむ。
※java8、IDEはSTSを使用しております。IDEのInstallなど、事前に必要な手順は既に済ませているものとして進めていきます。
Spring Initializerを使ってプロジェクトを作成すると、下記のようなファイルが作成されているかと思います。
package com.example.demo; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class DemoApplication { public static void main(String[] args) { SpringApplication.run(DemoApplication.class, args); } }
@SpringBootApplication
@SpringBootApplicatinには、@Configuration,@EnableAutoConfiguration,@ComponentScanが内包されており、
この@SpringBootApplicationのアノテーション一つで、
- このクラスがコンフィギュレーション(設定)クラスであり(@Configuration)、
- AutoConfig(自動設定)の有効化を行い(@EnableAutoConfiguration)、
- AutoConfigの対象として、このクラスのパッケージ配下にあるBeanを指定する(@ComponentScan)、
といったことを行っています。
runメソッドの引数には、@EnableAutoConfigrurationを付与したクラスを指定する、というルールがありますが、 @SpringBootApplicationに内包されているため、問題なく動作します。
ちなみに、@EnableAutoConfigrationの上にカーソルがある状態でジャンプ(「F3」押下)すると EnableAutoConfigrationのクラス宣言の上に下記のような記述があると思います。
@Import(EnableAutoConfigurationImportSelector.class) public @interface EnableAutoConfiguration {
@EnableAutoConfigurationには、別のコンフィギュレーションクラスをインポートすることを示すアノテーション(@Import)が指定されており、インポートされるコンフィギュレーションクラスはorg.springframework.boot.autoconfigure.EnableAutoConfigurationImportSelectorクラスの実装によって決まります。EnableAutoConfigurationImportSelectorの実装では、クラスパス上の/META-INF/spring.factoriesよりインポート対象のコンフィギュレーションクラスを取得するようになっており、以下のコンフィギュレーションクラスがインポート対象になっています。
(こちら)https://qiita.com/kazuki43zoo/items/8645d9765edd11c6f1ddの記事から引用させて頂きました。(非常に詳しく、また、大変分かりやすい説明となっているので一読をオススメします。)
この働きにより、大量のコンフィギュレーションクラスがimportされ、開発者自身での設定に代わって、必要な設定を、Spring Boot側で処理しています。